interview
personal blog
- 代码优化
- remove axios,use $fetch
- remove highlight.js
- remove alicdn, use custom cdn
- 自定义拆包
rollupOptions.output.manualChunks
- preload
- 字体文件预加载
- Accessiblity 优化
<a class="pc" aria-label="website">
- 代理服务器缓存
- nginx 反向代理设置缓存
- cdn 缓存
- 静态资源开启 cdn 缓存
- redis 缓存
- 相同请求使用 redis 缓存处理
- 更新/添加/删除文章,删除缓存
ECMAScript
变量提升
javascript 代码在执行前,需要先编译。
在编译阶段,变量和函数会被存放到变量环境中,变量的默认值会被设置为 undefined,代码执行阶段,javascript 引擎会从变量环境中去查找自定义的变量和函数。
调用栈
javascript 引擎会用调用栈来维护函数之间的关系。
每调用一个函数,JavaScript 引擎都会为其创建执行上下文,并把该执行上下文压入调用栈,然后再执行函数代码。
块级作用域
作用域是指程序中定义变量的区域,该位置决定了变量的生命周期。
通俗地理解,作用域就是变量与函数的可访问范围,即作用域控制变量和函数的可见性和生命周期。
ES6 之前只有全局作用域和函数作用域,ES6 引入块级作用域。
javascript 引擎是通过变量环境实现函数作用域,通过词法环境实现块级作用域(let、const)。
作用域链、闭包
词法作用域就是指作用域是由代码中函数声明的位置决定的,词法作用域是静态作用域,通过它可以预测代码在执行过程中如何查找标识符。
一个函数和对周围状态的引用捆绑在一起,这样的组合就是闭包。闭包可以让你在一个内层函数中访问到其外层函数的作用域。
如果引用闭包的函数是一个全局变量,闭包会一直在内存中直到页面关闭(如果闭包以后不再使用,就会造成内存泄露)。
如果引用闭包的函数是一个局部变量,函数销毁后,下次 JS 引擎进行垃圾回收时,判断内存不再使用,就会回收这块内存。
delete
delete 语法设计是删除一个表达式的结果
delete x 是在删除一个表达式的、引用类型的结果(result),而不是再删除 x 表达式,或者这个删除表达式的值(Value)。
当 x 是全局对象 global 的属性时,delete x 其实只需要返回 global.x 这个引用就可以。 当它不是全局对象 global 的属性时,那么就需要从当前环境下找到一个名为 x 的引用。 找到这两种不同的引用的过程,称为 ResolveBinding,这两种不同的 x,称为不同环境下绑定的标识符/名字。
const name = "123";
age = 18;
Object.getOwnPropertyDescriptor(window, 'name'); // { configurable: true, value: '123', enumerable: true }
Object.getOwnPropertyDescriptor(window, 'age'); // { configurable: true, enumerable: true, value: 18, writable: true }
console.log(delete name) // false
console.log(delete age) // true
console.log(typeof age) // undefinedconst name = "123";
age = 18;
Object.getOwnPropertyDescriptor(window, 'name'); // { configurable: true, value: '123', enumerable: true }
Object.getOwnPropertyDescriptor(window, 'age'); // { configurable: true, enumerable: true, value: 18, writable: true }
console.log(delete name) // false
console.log(delete age) // true
console.log(typeof age) // undefinednetwork
TCP/IP 网络分层模型
从下向上划分。
- 链接层(link layer)
- 以太网、Wifi 底层网络发送原始数据包,工作在网卡层次,使用 MAC 标记网络设备
- 网际层或者网络互联层(internet layer),IP 协议就处于这一层
- IP 协议定义了 IP 地址,可以在链接层基础上,用 IP 地址取代 MAC 地址
- 传输层(transport layer)
- TCP、UDP 协议工作层次
- 应用层(application layer)
- HTTP、Telnet、SSH、FTP、SMTP 等
OSI 网络分层模型
开放式系统互通通信参考模型(Open System Interconnection Reference Model)。仅是一个参考,并不是强制标准。
从下向上划分。
- 物理层,网络的物理形式
- 数据链路层,相当于 TCP/IP 的链接层
- 网络层,相当于 TCP/IP 的网际层
- 传输层,相当于 TCP/IP 的传输层
- 会话层,维护网络中连接状态,保持会话和同步
- 表示层,把数据转换为合适、可理解的语法和语义
- 应用层,面向具体的应用传输协议
五六七层统一对应 TCP/IP 的应用层。
HTTP
HTTP(HyperText Transfer Protocol) 是一个在计算机世界里用于专门在两点之间传输文本、图片、音频、视频等超文本数据的约定和规范。
HTTP 跑在 TCP/IP 协议栈之上,依靠 IP 协议实现寻址和路由、TCP 协议实现可靠数据传输、DNS 协议实现域名查找、SSL/TLS 协议实现安全通信。
特点:灵活可扩展、可靠的传输协议、应用层协议、使用请求-应答模式、无状态协议、明文传输、不安全
响应状态码
1xx:提示信息,目前是协议处理的状态,需要后续操作
- 101 Switch Protocols,客户端使用 Upgrade 头字段,要求协议升级,比如 WebSocket 。
2xx:成功态,报文已经收到并被正确处理
- 200 OK,常见成功状态码,响应头后通常存在 body 数据
- 204 No Content,常见成功状态码,响应头通常不存在 body 数据
- 206 Partial Content,HTTP 分块下载或断点续传的基础,客户端发送范围请求,服务端成功处理后,返回部分资源
- 206 通常伴随头字段 Content-Range
3xx:重定向,资源位置发生变动,需要客户端发送请求
- 301 永久重定向
- 302 临时重定向
- 304 Not Modified 表示资源未修改
4xx:客户端错误,请求报文错误,服务器无法处理
- 400 Bad Request,通用的错误,表示请求报文错误
- 403 Forbidden,服务端禁止访问资源
- 404 Not Found,本意服务器无法提供资源,未找到资源
- 405 Method Not Allowed,不允许使用某些方法操作资源
- 408 Request Timeout,请求超时
5xx:服务端错误,服务器处理时内部发生错误
- 500 Internal Server Error,通用错误码
- 502 Bad Gateway,服务器网关错误或者代理错误
- 503 Service Unavailable,服务器正忙,无法响应服务,503 是一个临时状态
HTTP 各版本差异
HTTP/0.9 1991 年发布的原型版本
- 只支持纯文本内容
- 仅支持 GET 命令
HTTP/1.0 1993 年发布
- 传入的内容不再局限于文本,可以发送任何格式内容
- 引入 HEAD、POST 等新方法
- 引入 HTTP Header 概念,每次通信都必须包含头信息,用来描述一些元数据
- 引入协议版本号概念
- 增加响应状态码
- 不支持断点续传
HTTP/1.1
引入持久连接
- TCP 默认不关闭,可以被多个请求复用,不需要显示声明 "Connection: keep-alive"
- 长连接连接时长可以通过请求头中的 keep-alive 设置
引入管线机制,同一个 TCP 连接里,客户端可以发送多个请求
增加缓存管理和控制
- 增加 E-Tag、If-Modified-Since、If-Match、If-None-Match 等字段
支持断点续传
- 使用请求头的 Range 来实现
允许响应数据分块(chunked),利用传输大文件
新增方法 PUT、DELETE、PATCH、OPTIONS 新方法
HTTP/2
二进制分帧
- 采用二进制格式,这样报文格式就被拆分为一个个乱序的二进制帧,用
Headers帧存放头部字段,Data帧存放请求体数据等,因为不需要排队等待,一定程度上解决了队头阻塞问题
- 采用二进制格式,这样报文格式就被拆分为一个个乱序的二进制帧,用
头部压缩
HTTP/1.1版本会出现User-Agent/Cookie/Accept/Server/Range等字段可能会占用几百甚至几千字节,而Body却经常只有几十字节,导致头部偏重,HTTP/2使用HPACK算法进行压缩
多路复用
- 复用
TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,且不用按顺序一一对应,一定程度上解决了队头阻塞的问题
- 复用
服务器推送
- 允许服务器未经请求,主动向客户端发送资源,即服务器推送
请求优先级
- 可以设置数据帧的优先级,让服务端先处理重要资源,优化用户体验
HTTP/3
QUIC 协议
- 运行在
QUIC之上的HTTP协议被称为HTTP/3,QUIC协议基于UDP实现,同时也整合了TCP、TLS和HTTP/2的优点,并加以优化
- 运行在
零 RTT 建立连接
- 首次连接只需要
1 RTT,后面的连接更是只需0 RTT,意味着客户端发给服务端的第一个包就带有请求数据
- 首次连接只需要
连接迁移
QUIC连接不以四元组(源IP、源端口、目的IP、目的端口)作为标识,而是使用一个64位的随机数,这个随机数被称为Connection ID,即使IP或者端口发生变化,只要Connection ID没有变化,那么连接依然可以维持
多路复用
QUIC的传输单元是Packet,加密单元也是Packet,整个加密、传输、解密都基于Packet,这样就能避免TLS的队头阻塞问题QUIC基于UDP,UDP的数据包在接收端没有处理顺序,即使中间丢失一个包,也不会阻塞整条连接,其他的资源会被正常处理
改进的拥塞控制
- 热插拔,
TCP中如果要修改拥塞控制策略,需要在系统层面进行操作,QUIC修改拥塞控制策略只需要在应用层操作,并且QUIC会根据不同的网络环境、用户来动态选择拥塞控制算法 - 前向纠错
FEC,使用前向纠错(FEC,Forward Error Correction)技术增加协议的容错性,一段数据被切分为10个包后,依次对每个包进行异或运算,运算结果会作为FEC包与数据包一起被传输,如果不幸在传输过程中有一个数据包丢失,那么就可以根据剩余9个包以及FEC包推算出丢失的那个包的数据 - 单调递增的
Packet Number,与TCP的Sequence Number不同的是,Packet Number严格单调递增,如果Packet N丢失了,那么重传时Packet的标识不会是N,而是比N大的数字,比如N + M,这样发送方接收到确认消息时就能方便地知道ACK对应的是原始请求还是重传请求 - 更多的
ACK块,QUIC最多可以捎带256个ACK block,在丢包率比较严重的网络下,更多的ACK block可以减少重传量,提升网络效率
- 热插拔,
流量控制
TCP会对每个TCP连接进行流量控制,而QUIC只需要建立一条连接,在这条连接上同时传输多条Stream
WebSocket
WebSocket 协议依赖于 HTTP。
WebSocket 是一个 “全双工” 的通讯协议,与 TCP 一样,客户端和服务端都可以随时向对方发送数据。
WebSocket 握手是一个标准的 HTTP Get 请求。
但是要带上两个协议升级的头字段:
- Connection: Upgrade,表示要求协议升级
- Upgrade: websocket,表示要升级成 WebSocker 协议
还增加了两个额外的认证头字段:
- Sec-WebSocket-Key:一个 base64 编码的 16 字节随机数,作为简单的认证密钥
- Sec-WebSocket-Version:协议版本号,当前必须是 13
服务端会返回特殊的 “101 Switching Protocols” 响应报文,接下来请求就用 HTTP,改用 WebSocket 协议进行通信。
HTTPS、SSL\TLS
https 主要用来解决 http 的缺点,明文传输和不安全。
如果通信过程具备机密性、完整性、身份认证和不可否认,就可以认为是安全的。
- 机密性,数据保密,不能让不相关的人看到消息
- 完整性,数据传输过程中不会被修改
- 身份认证,可以确认对方身份,保证消息发送给可信的人
- 不可否认,不能否认已经发生过的行为
https 在 http 的基础之上增加了上面所说的 3 大特性。
https 其实就是把 HTTP 下层的传输协议由 TCP/IP 协议换成 SSL/TLS,即 HTTP Over SSL/TLS。
SSL 即安全套接层(Secure Sockets Layer),位于 OSI 模型中的第 5 层。于网景公司 1994 年发明,有 v2、v3 两个版本。
1999 年互联网工程组 IETF 把它改名为 TLS(传输层安全,Transport Layer Security),正式标准化,版本号从 1.0 开始,所以 TLS 1.0 实际就是 SSL v3.1。
目前应用广泛的 TLS 是 1.2。TLS 协议由记录协议、握手协议、警告协议、变更密码规范协议、扩展协议等几个子协议组成,综合使用了对称加密、非对称加密、身份认证等许多密码学前沿技术。
浏览器和服务器使用 TLS 建立连接时需要选择一组恰当的加密算法和实现安全通信,这些算法的组合被称为 “密码套件”(cipher suite,加密套件)。
TLS 密码套件命名非常规范,基础形式是 “密钥交换算法 + 签名算法 + 对称加密算法 + 摘要算法”。
以下面的密码套件为例:
ECDHE-RSA-AES256-GCM-SHA384ECDHE-RSA-AES256-GCM-SHA384握手时使用 ECDHE 算法进行密钥交换,使用 RSA 签名和身份认证,握手后的通信使用 AES 对称算法,密钥长度 256 位,分组模式是 GCM,摘要算法 SHA384 用于消息认证和产生随机数。
TLS 中使用混合加密方式,实现机密性。
- 通信刚开始使用非对称加密算法,比如 RSA、ECDHE 解决密钥交换的问题。
- 完成会话密钥安全交换之后,后续不再使用非对称加密,全部使用对称加密。
TLS 中使用摘要算法(Digest Algorithm)实现完整性。
- 摘要算法是特殊的 “单向” 加密算法,它只有算法,没有密钥,加密后的数据无法解密。
- 摘要算法保证 “数字摘要” 和原文是完全等价的。只要在原文后附上它的摘要,就能够保证数据的完整性。
- 摘要算法不具备机密性,明文传输同样也存在问题,所以 TLS 在传输过程会使用会话密钥同时加密消息和摘要。
TLS 中使用数字签名同时实现身份认证和不可否认。
- 私钥只能本人持有,其他任何人都不会拥有。
- 使用私钥加上摘要算法,就可以实现 “数字签名”。私钥仅加密原文摘要,形成数字签名,使用公钥对其进行解析,获取摘要后,比对原文验证其完整性。
- 上述两个行为存在两个专业术语,叫做 “签名” 和 “验签”。
- 对于 “公钥信任” 问题,需要通过 CA(Certificate Authority,证书认证机构)构建起公钥信任链,保证公钥是安全可靠的。
数字证书和 CA
- 公钥的分发需要使用数字证书,必须由 CA 的信任链来验证,否则就是不可信的。
- CA 证书中包含要发给客户端的公钥、签发者、过期时间等信息。
- 数字签名和数字证书仅用于 TSL/SSL 的握手阶段,用来保证服务器的公钥能够正确地传递给浏览器。
证书信任链过程:
以二级 CA 证书为例,服务器返回的是证书链(不包括根证书)。 浏览器获取到证书链,会根据证书链中的签发者信息,逐层向上查找到根证书,并从根证书开始逐级向下做验签。 首先使用信任的根证书(公钥)解析证书链的根证书得到一级证书的公钥和摘要验签,然后拿一级证书的公钥解密一级证书拿到二级证书的公钥和摘要验签,再然后拿二级证书的公钥解密二级证书得到服务器的公钥和摘要验签,验证过程结束。
验签过程:
首先证书包括四部分:
- signedCertificate 签名的证书,即浏览器点击小锁头直观可以看到的证书
- algorithmIdentifier 算法标记,包括了签名证书用到的摘要和签名算法
- encrpted 加密摘要,加密摘要不包含在 signedCertificate 中,浏览器中点击小锁头看不到加密摘要
使用传递过来的摘要算法 algorithmIdentifier 对一级证书的 signedCertificate 做摘要。 使用根证书解密解析一级证书的数字签名 encrpted,得到发过来的摘要。 如果两者一致,则认为一级 CA 证书是真实有效的。
如果中间人截获证书,将证书替换为自己申请的证书,并且使客户端信任中间人的根证书,这样中间人就可以使用这个根证书来 “伪造” 证书,冒充原网站, fiddler 就是这么做的。简单修改证书是不行的,因为证书会被 CA 签名,可以防止被篡改,中间人得不到 CA 的私钥,就没办法伪造。
TLS 1.2 连接过程
TLS 协议包含几个子协议,也可以理解为几个不同职责的模块,常见的有记录协议、警报协议、握手协议、变更密码协议等。
- 记录协议(Record Protocol)规定 TLS 收发收据的基本单位:记录(Record)。
- 类似 TCP 里的 segment,所有的其他子协议都需要记录协议发出。
- 多个记录数据可以在一个 TCP 包里一次性发出,不需要像 TCP 那样返回 ACK。
- 警报协议(Alert Protocol)的职责是像对方发送警告信息
- 类似 HTTP 协议里的状态码
- protocol_version 就是不支持旧版本,bad_certificate 就是证书有问题
- 握手协议(Handshake Protocol)是 TLS 里最复杂的子协议
- 比 TCP 的 SYN/ACK 复杂的多
- 浏览器和服务器会在握手过程中协商 TLS 版本号、随机数、密码套件等信息,然后交换证书和密钥参数,最终双方协商得到会话密钥
- 变更密码规范协议(Change Cipher Spec Protocol)
- 非常简单,就是一个 “通知”,告诉对方,后续数据都将使用加密保护
TLS 握手过程简要图。

ECDHE 握手过程
下图是 TLS 的握手过程。

TCP 建立连接之后:
浏览器会发送 “Client Hello” 消息。包含客户端的版本号、支持的密码套件,还有一个随机数(Client Random),用于生成会话密钥。
Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Random: 1cbf803321fd2623408dfe…
Cipher Suites (17 suites)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (0xc02f)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Random: 1cbf803321fd2623408dfe…
Cipher Suites (17 suites)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (0xc02f)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)服务器收到 “Client Hello” 后,返回 “Server Hello” 消息,对比版本号,也会给出一个随机数(Server Random),然后从客户端的列表里选择一个本次通信要使用的密码套件。假定这里选择 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384。
Handshake Protocol: Server Hello
Version: TLS 1.2 (0x0303)
Random: 0e6320f21bae50842e96…
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)Handshake Protocol: Server Hello
Version: TLS 1.2 (0x0303)
Random: 0e6320f21bae50842e96…
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)然后服务器为了证明自己的身份,还要把证书发送给客户端(Server Certificate)。
其次因为服务器选择 ECDHE 算法,所以会在发送证书后,发送 “Server Key Exchange” 消息,里面是椭圆曲线的公钥(Server Params),用来实现密钥交换算法,再加上自己的私钥签名认证。
Handshake Protocol: Server Key Exchange
EC Diffie-Hellman Server Params
Curve Type: named_curve (0x03)
Named Curve: x25519 (0x001d)
Pubkey: 3b39deaf00217894e...
Signature Algorithm: rsa_pkcs1_sha512 (0x0601)
Signature: 37141adac38ea4...Handshake Protocol: Server Key Exchange
EC Diffie-Hellman Server Params
Curve Type: named_curve (0x03)
Named Curve: x25519 (0x001d)
Pubkey: 3b39deaf00217894e...
Signature Algorithm: rsa_pkcs1_sha512 (0x0601)
Signature: 37141adac38ea4...最后服务器发送 “Server Hello Done” 消息。
这样第一个消息往返就结束了,共发送两个 TCP 包,客户端和服务端通过明文共享了三个信息,Client Random、Server Random 和 ServeParams。
客户端此时已经拿到服务器的根证书,会开始走证书链验证,确认证书的真实性,再用证书公钥验证签名,就可以确认服务器身份。可以继续往下执行。
客户端按照密码套件的要求,也生成一个椭圆曲线的公钥(Client Params),发送 “Client Key Exchange” 消息给服务器。
Handshake Protocol: Client Key Exchange
EC Diffie-Hellman Client Params
Pubkey: 8c674d0e08dc27b5eaa…Handshake Protocol: Client Key Exchange
EC Diffie-Hellman Client Params
Pubkey: 8c674d0e08dc27b5eaa…此时客户端和服务器都拿到了密钥交换算法的两个参数(Client Params、Server Params),然后使用 ECDHE 算法计算得到 “Pre-Master”,也是一个随机数。
现在客户端和服务器手里就存在了三个随机数:Client Random、Server Random、Pre-Master。用这三个数可以生成用于加密会话的主密钥,即 “Master-Secret”。
master_secret = PRF(pre_master_secret, "master secret", ClientHello.random + ServerHello.random)
RPF 是伪随机数函数,基于密码套件中的最后一个参数,比如本次密码套件中的 SHA384,通过摘要算法再一次强化 “Master Secret” 的随机性。
主密钥有 48 字节,它也不是最终用于通信的会话密钥,还会用 PRF 扩展出更多的密钥,比如客户端发送的会话密钥(client_write_key)、服务器发送的会话密钥(server_write_key)等,避免只使用一个密码带来的安全隐患。
有了主密钥和派生的会话密钥,握手就快结束了。
客户端发送 “Change Cipher Spec”,然后再发送 “Finished” 消息,把之前发送的数据做一个摘要,加密一下让服务器做验证。
服务器也是同样的操作,发送 “Change Cipher Spec” 和 “Finished” 消息,双方都验证加密解析 OK,握手正式结束,后面就收发被加密的 HTTP 请求和响应了。
“Client Params 和 Server Params 都可以被截获,为何中间人没法通过这两个信息计算 Pre-Master Secret 呢?
- 客户端随机生成随机值 Ra,计算 Pa(x, y) = Ra * Q(x, y),Q(x, y) 为全世界公认的某个椭圆曲线算法的基点。将 Pa(x, y) 发送至服务器。
- 服务器随机生成随机值 Rb,计算 Pb(x,y) = Rb * Q(x, y)。将 Pb(x, y) 发送至客户端。
- 客户端计算 Sa(x, y) = Ra * Pb(x, y),服务器计算 Sb(x, y) = Rb * Pa(x, y)
- 算法保证了Sa = Sb = S,提取其中的 S 的 x 向量作为密钥(预主密钥)
RSA 握手过程
刚才说的 ECDHE 握手过程,是目前主流的 TLS 握手过程,这与传统的握手有两点不同。
- 使用 ECDHE 实现密钥交换,而不是 RSA,所以在服务端会发出 “Server Key Exchange” 消息。
- 因为使用 ECDHE,客户端可以不用等到服务器返回 “Finished” 确认握手完毕,立即就发出 HTTP 报文,省去一个消息往返的时间。不等连接完全建立就提前发送应用数据,提高传输的效率。

双向认证
上面所说的只是 “单向认证” 握手过程,只认证了服务器身份,并没有认证客户端身份。
这是因为通常单向认证后就已经建立了安全通信,用账号、密码等简单的手段就可以确认用户的真实身份。
为了防止账号、密码被盗,例如网上银行还会使用 U 盾给用户颁发客户端的证书,实现 “双向认证”,这样会更加安全。双向认证的流程也没有太多变化,只是在 “Server Hello Done” 之后,“Client Key Exchange” 之前,客户端端要发送 “Client Certificate” 消息,服务器收到后也要把证书链走一遍,验证客户端身份。
TLS 1.3 特性分析
TLS 1.3 与 2018 年发布,它有三个主要改进目标:兼容、安全与性能。
兼容性
TLS 1.3 在保持 TLS 1.2 现有的记录格式不变的前提下,通过 “伪装” 实现兼容。
TLS 1.3 使用一个新的扩展协议(Extension Protocol),通过在记录末尾添加一系列的 “扩展字段” 来增加新的功能,并实现 “向后兼容”。
记录头的 Version 字段被固定的前提下,TLS 1.3 协议握手的 “Hello” 消息后面都会有 “supported_versions” 扩展,它用于标记 TLS 版本号,使用它就可以区分新旧协议。
Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Extension: supported_versions (len=11)
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Extension: supported_versions (len=11)
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)TLS 1.3 利用扩展实现了许多重要功能,比如 “supported_groups”、“key_share”、“signature_algorthms”、“server_name” 等。
强化安全
TLS 1.2 也有很多漏洞和加密算法的弱点,TLS 1.3 在协议里修补了这些不安全因素。
- 伪随机数函数由 PRF 升级为 HKDF(HMAC-based Extract-and-Expand Key Derivation Function);
- 明确禁止在记录协议里使用压缩;
- 废除了 RC4、DES 对称加密算法;
- 废除了 ECB、CBC 等传统分组模式;
- 废除了 MD5、SHA1、SHA-224 摘要算法;
- 废除了 RSA、DH 密钥交换算法和许多命名曲线。
TLS 1.3 只保留了 AES、ChaCha20 对称加密算法,分组模式只能用 AEAD 的 GCM、CCM 和 Poly1305,摘要算法只能用 SHA256、SHA384,密钥交换算法只有 ECDHE 和 DHE,椭圆曲线只剩下 P-256 和 x25519 等 5 种。
废除 RSA 和 DH 密钥交换算法的原因:
RSA 不具备 “前向安全”(Forward Secrecy)。如果一个黑客一直在长期收集混合加密系统收发的所有报文,一旦私钥泄露或被破解,那么黑客就能够使用私钥解密出之前所有报文的 “Pre-Master”,再算出会话密钥,破解所有密文。
ECDHE 算法会在每次握手时都生成一对临时的公钥和私钥,每次通信的密钥对都是不同的,即使黑客破解这一次的会话密钥,也只是这次通信被攻击,历史消息不会受到影响,仍然是安全的。
提升性能
HTTPS 建立连接时不仅要做 TCP 握手,还要做 TLS 握手,在 TLS 1.2 中会多花两个消息往返时间(2-RTT),可能会导致几十毫秒甚至上百毫秒的延迟,在移动网络中延迟还会更加严重。
TLS 1.3 压缩了以前的 “Hello” 协商过程,删除 “Key Exchange” 消息,把握手时间减少到 “1-RTT”,效率提升一倍。客户端在 “Client Hello” 消息里直接用 “suppported_groups” 带上支持的曲线,比如 P-256、X25519,用 “key_share” 带上曲线对应的客户端公钥参数,用 “signuture_algorithms” 带上签名算法。
服务器收到后会在这些扩展里选定一个曲线和参数,再用 “key_share” 扩展返回服务器这边的公钥参数,就实现了双方的密钥交换。

TLS 1.3 握手分析

TCP 建立连接后,浏览器首先还是会发一个 “Client Hello”。
因为 1.3 的消息兼容 1.2,所以开头的版本号、支持的密码套件和随机数(Client Random)结构都是一样的(随机数是 32 个字节)。
Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Random: cebeb6c05403654d66c2329…
Cipher Suites (18 suites)
Cipher Suite: TLS_AES_128_GCM_SHA256 (0x1301)
Cipher Suite: TLS_CHACHA20_POLY1305_SHA256 (0x1303)
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Extension: supported_versions (len=9)
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)
Extension: supported_groups (len=14)
Supported Groups (6 groups)
Supported Group: x25519 (0x001d)
Supported Group: secp256r1 (0x0017)
Extension: key_share (len=107)
Key Share extension
Client Key Share Length: 105
Key Share Entry: Group: x25519
Key Share Entry: Group: secp256r1Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Random: cebeb6c05403654d66c2329…
Cipher Suites (18 suites)
Cipher Suite: TLS_AES_128_GCM_SHA256 (0x1301)
Cipher Suite: TLS_CHACHA20_POLY1305_SHA256 (0x1303)
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Extension: supported_versions (len=9)
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)
Extension: supported_groups (len=14)
Supported Groups (6 groups)
Supported Group: x25519 (0x001d)
Supported Group: secp256r1 (0x0017)
Extension: key_share (len=107)
Key Share extension
Client Key Share Length: 105
Key Share Entry: Group: x25519
Key Share Entry: Group: secp256r1“supported_versions” 表示这是 TLS 1.3,“supported_groups” 是支持的曲线,“key_share” 是曲线对应的参数。
服务器收到 “Client Hello” 消息后,会返回 “Server Hello” 消息,还要给出一个随机数(Server Random)和选定的密码套件。
Handshake Protocol: Server Hello
Version: TLS 1.2 (0x0303)
Random: 12d2bce6568b063d3dee2…
Cipher Suite: TLS_AES_128_GCM_SHA256 (0x1301)
Extension: supported_versions (len=2)
Supported Version: TLS 1.3 (0x0304)
Extension: key_share (len=36)
Key Share extension
Key Share Entry: Group: x25519, Key Exchange length: 32Handshake Protocol: Server Hello
Version: TLS 1.2 (0x0303)
Random: 12d2bce6568b063d3dee2…
Cipher Suite: TLS_AES_128_GCM_SHA256 (0x1301)
Extension: supported_versions (len=2)
Supported Version: TLS 1.3 (0x0304)
Extension: key_share (len=36)
Key Share extension
Key Share Entry: Group: x25519, Key Exchange length: 32“supported_versions” 确认使用 TLS 1.3,“key_share” 扩展中带上曲线和对应的公钥参数。
这时只交换了两条消息,客户端和服务端就拿到四个共享信息:Client Random 和 Server Random、Client Params 和 Server Params,两边就可以各自利用 ECDHE 算出 “Pre-Master”,再用 HKDF 生成主密钥 “Master Secret”,效率比 TLS 1.2 提高很多。
算出主密钥后,服务器立刻发出 “Change Cipher Spec” 消息,比 TLS 1.2 提早进入加密通信,后面的证书等就是加密的,减少了握手时的明文信息泄露。
这里 TLS 1.3 还有一个安全强化措施,多了个 “Certificate Verify” 消息,用服务器的私钥把前面的曲线、套件、参数等数据加了签名,作用和 “Finished” 消息差不多。但因为是私钥签名,所以强化了身份认证和防篡改。
这两个 “Hello” 消息之后,客户端验证服务器证书,再发 “Finished” 消息,就正式完成握手,开发收发 HTTP 报文。
HTTPS 优化
HTTP 连接大致上可以划分为两部分,一部分是建立连接时的非对称加密握手,另一部分是握手后的对称加密报文传输。
因为目前的 AES、ChaCha 20 性能都很好,还有硬件优化,报文传输的性能损耗并不大。所以,通常所说的 “HTTPS” 连接慢指的是刚开始建立连接的那段时间。
TCP 建立连接之后,正式数据传输之前,HTTPS 比 HTTP 增加了 TLS 握手的步骤,这个步骤最长可以花费 2-RTT。并且在握手消息的网络耗时之外,还有其他的一些 “隐性” 消耗:
- 用于密钥交换的临时公私钥对(ECDHE);
- 验证证书时访问 CA 获取 CRL 或者 OSCP;
- 非对称加密解密处理 “Pre-Master”。
最差情况下,HTTPS 建立连接可能会比 HTTP 慢几百毫秒甚至几秒,这其中既有网络耗时,也有计算耗时。不过目前已经有很多行之有效的HTTPS 优化手段,运用得好可以把连接的额外耗时降低到几十毫秒甚至是 “零”。
下面这张图中已经把 TLS 握手过程中影响性能的部分都标记出来。

硬件优化
首先,可以选择更快的 CPU,最好可以内建 AES 优化,这样既可以加速握手,也可以加速传输。
其次,可以选择 “SSL 加速卡”,加解密时调用它的 API,让专门硬件来做非对称加解密,分担 CPU 计算压力。
SSL 加速卡缺点:升级慢、支持算法有限,不能灵活定制解决方案等
最后,我们还可以选择 “SSL 加速服务器”。用专门的服务器集群来彻底 “卸载” TLS 握手时的加解密计算。
软件升级
软件升级即把现在正在使用的软件尽量升级到最新版本。例如 Linux 内核、Nginx 版本、OpenSSL 版本。
协议优化
尽可能使用 TLS 1.3,它大幅度简化了握手进程,完全握手只需要 1-RTT,而且更安全。
如果不能升级 1.3,只能使用 1.2,握手使用的密钥交换尽量选用椭圆曲线的 ECDHE 算法。
ECDHE 算法运算速度快,安全性高,还支持 “False Start”,能够把握手的消息往返减少到 1-RTT。
椭圆曲线最好选择是 x25519,其次是 P-256。对称加密算法,可以选用 “AES_128_GCM”。
Nginx 里可以使用 “ssl_ciphers”、“ssl_ecdh_curve” 等指令配置服务器使用的密码套件和椭圆曲线优先级。
ssl_ciphers TLS13-AES-256-GCM-SHA384:TLS13-CHACHA20-POLY1305-SHA256:EECDH+CHACHA20;
ssl_ecdh_curve X25519:P-256;
ssl_ciphers TLS13-AES-256-GCM-SHA384:TLS13-CHACHA20-POLY1305-SHA256:EECDH+CHACHA20;
ssl_ecdh_curve X25519:P-256;证书优化
除了密钥交换,握手过程中的证书验证也是一个比较耗时的操作。这里有两个优化点,一个是证书传输、一个是证书验证。
服务器证书可以选择椭圆曲线(ECDSA)证书而不是 RSA 证书。
224 位的 ECC 比 2048 位的 RSA 量级小很多,既能够节约带宽也能够减少客户端运算量。
使用 OCSP(在线证书状态协议,Online Certificate Status Protocol),向 CA 发送查询请求,返回证书有效状态。
还可以安装 “OCSP Sttaping” 补丁,它可以让服务器预先访问 CA 获取 OCSP 响应,然后在握手时随证书一起发给客户端,免去客户端连接 CA 的查询时间。
Nginx 里可以用指令 “ssl_stapling on” 开启 “OCSP Stapling”。
会话复用
HTTPS 连接的过程中,需要计算主密钥 “Master Secret”,主密钥每次连接时都要重新计算,将主密钥缓存重用,就可以避免握手和计算成本。这种做法就是 “会话复用”(TLS session resumption)。
会话复用分为两种,分别是 “Session ID” 和 “Session Ticket”。
“Session ID” 就是客户端和服务器首次连接后各自保存一个会话的 ID 号,内存里存储主密钥和其他相关的信息。当客户端再次连接时发一个 ID 过来,服务器就在内存里找,找到就直接用主密钥恢复会话状态,跳过证书验证和密钥交换过程,只用一个消息往返就可以建立安全通信。
“Session ID” 是最早出现的会话复用技术,应用最广,但它也有缺点,服务器必须保存每一个客户端的会话数据,对于拥有百万、千万级别用户的网站来说需要存储大量数据,会加重服务器负担。
“Session Ticket” 类似于 HTTP 的 Cookie,就是将存储的责任由服务器转移到客户端,服务器加密会话信息,用 “New Session Ticket” 消息发送给客户端,让客户端保存。
重连的时候,客户端使用扩展 “session_ticket” 发送 “Ticket” 而不是 “Session ID”,服务器解密后验证有效期,就可以恢复会话,开始加密通信。
“Session Ticket” 需要使用一个固定的密钥文件(ticket_key)来加密 Ticket,为了防止密钥被破解,保证 “前向安全”,密钥文件需要定期轮换,比如设置一小时或者一天。
预共享密钥
“False Start”、“Session ID”、“Session Ticket” 等方式只能实现 1-RTT。TLS 1.3 中进一步实现了 “0-RTT”,原理和 “Session Ticket” 类似,但在发送 Ticket 时会带上应用数据(Early Data),免去 1.2 里的服务器确认步骤,这种方式称为 “Pre-shared Key”,简称 “PSK”。
“PSK” 并不是完美的,它为了追求效率牺牲了安全性,容易受到 “重放攻击”(Replay attack)威胁。
单点登录(SSO)
https://mp.weixin.qq.com/s/6d_16hfd5Fz8pZvdpO3BEw
相对于单系统登录, SSO 需要一个认证中心,只有认证中心接受用户的用户名密码等安全信息,其他系统不再提供登录入口,只接受认证中心的间接授权。
间接授权通过令牌实现,SSO 认证中心验证用户的用户名密码没问题,创建授权令牌,在接下来的跳转过程中,授权令牌作为参数发送给各个子系统,子系统呢到令牌,得到授权之后,可以借此创建局部会话,局部会话登录方式与单系统登录方式相同。这个过程就是单点登录系统的原理。

typescript
typescript 是拥有类型系统的超集,可以编译为 JavaScript。
typescript 支持类型检查,语言扩展,可以帮助团队成员重塑 “类型思维”,接口提供方可以被迫思考 API 边界,从代码编写者变为代码设计者。
javascript 是一门动态类型、弱类型的语言。
基础类型
最新的 ECMAScript 标准定义了8种数据类型
- 基本数据类型:boolean、null、undefined、number、BigInt、string、symbol
- 引用类型:Object
Boolen、null、undefined、Number、String、Symbol、Object、Array、FunctionBoolen、null、undefined、Number、String、Symbol、Object、Array、FunctionTypeScript 数据类型:
Boolen、null、undefined、Number、String、Symbol、Object、Array、Function
void、any、never、元组、枚举、高级类型等Boolen、null、undefined、Number、String、Symbol、Object、Array、Function
void、any、never、元组、枚举、高级类型等枚举
一组有名字的常量集合
枚举成员分为两类:
常量枚举(const enum),它会在编译的时候计算出结果,然后以常量的形式出现在运行时环境
计算枚举(computed enum),是一些非常量的表达式 ,这些类型的值不会再编译时计算,而是会保留到程序的执行阶段
enum Char {
a,
b = Char.a,
c = 1 + 3,
d = Math.random(),
e = '123'.length
}enum Char {
a,
b = Char.a,
c = 1 + 3,
d = Math.random(),
e = '123'.length
}我们可以将程序中不容易记忆的硬编码或者在未来中可能改变的常量,抽离出来定义成枚举类型,可以提高程序的可读性和可维护性。
给定字符串 “a”,获取 Test.A
enum Test {
A = 'a',
B = 'b',
c = 'C'
}
function getKey(value: string) {
let key: keyof typeof Test
for (key in Test) {
if (value === Test[key]) return key
}
return null
}enum Test {
A = 'a',
B = 'b',
c = 'C'
}
function getKey(value: string) {
let key: keyof typeof Test
for (key in Test) {
if (value === Test[key]) return key
}
return null
}接口
接口可以用来约束对象、函数以及类的结构和类型,它是一种代码协作的契约,我们必须遵守,而且不能改变。
泛型
使用泛型的好处:
- 函数和类可以轻松地支持多种类型,增强程序的扩展性
- 不必写多条函数重载,冗长的联合类型声明,增强代码可读性
- 灵活控制类型之间的约束关系
泛型不仅可以保持类型的一致性,又不失程序的灵活性,同时也可以通过泛型约束,控制类型之间的约束。从代码的上来看,可读性,简洁性,远优于函数重载,联合类型声明以及 any 类型的声明。
类型检查机制
类型推断
不需要指定变量的类型(函数的返回值类型),TypeScript 可以根据某些规则自动地为其推断出一个类型。
- 基础类型推断
- 最佳通用类型推断
- 上下文类型推断
类型兼容性
- 结构之间兼容:成员少的兼容成员多的。
- 函数之间兼容:参数多的兼容参数少的
类型保护
类型保护就是,TypeScript 能够在特定的区块中保证变量属于某种确认的类型。
- instanceof 判断实例是否属于某个类
- in 关键字
- typeof
- 通过类型保护函数
ts 的类型检查机制,分别是类型推断、类型兼容性、类型保护。
利用这些机制,再配合 IDE 的自动补全提示功能能够极大地提高我们的开发效率,需要我们善加利用。
高级类型
高级类型就是 ts 为了保持灵活性所引入的一些元特性。这些特性有助于我们应对复杂多变的开发场景。
交叉类型与联合类型
|、&
- 交叉类型指将多个类型合并为一个类型,新的类型具有所有类型的特性,交叉类型特别适合对象混用的场景
- 交叉类型取所有类型的并集
- 联合类型指声明的类型并不确定,可以为多个类型中的一个
索引类型
keyof、extends
- 索引类型的查询操作符:
keyof T,表示类型 T 的所有公共属性的字面量的联合类型 - 索引访问操作符:
T[K],表示对象 T 的属性 K 所代表的类型 - 泛型约束:
T extends U,表示泛型变量可以通过继承某个类型获得某些属性
// 使用索引类型改造 getValues 函数
// 索引类型可以实现对对象属性的查询和访问,然后再配合泛型约束就可以建立对象、对象属性以及属性值之间的约束关系。
function getValues<T, K extends keyof T>(obj: T, keys: K[]): T[K][] {
return keys.map(key => obj[key])
}// 使用索引类型改造 getValues 函数
// 索引类型可以实现对对象属性的查询和访问,然后再配合泛型约束就可以建立对象、对象属性以及属性值之间的约束关系。
function getValues<T, K extends keyof T>(obj: T, keys: K[]): T[K][] {
return keys.map(key => obj[key])
}映射类型
in
- 通过映射类型我们可以从一个旧的类型生成一个新的类型,比如说把一个类型的所有属性变为只读。
- 映射类型本质上是一种泛型接口,通常会结合索引类型获取对象属性和属性值,从而将一个对象映射成我们想要的结构。
type Readonly<T> = {
readonly [P in keyof T]: T[P];
}
// readonly 是一个泛型接口,而且是一个可索引的泛型接口
// 索引签名是 P in keyof T,T 是一个索引类型的查询操作符,表示类型 T 所有属性的联合类型
// P in 相当于执行了一次遍历,会把变量 P 依次的绑定到 T 的所有属性上
// 索引签名的返回值就是一个索引访问操作符,T[P] 这里代表属性 P 所指定的类型
// 最后再加上 readonly,就可以把所有的属性变成只读,这就是 Readonly 的实现原理
type Partial<T> = {
[P in keyof T]?: T[P];
}
// Partial 的实现几乎和 Readonly 一致,只不过把只读的属性变成可选
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
}
// 第一个参数 T 指定对象,第二个参数 K 存在一个约束,K 一定要来自 T 所有属性字面量的联合类型
// 新的属性的类型一定要在 K 的属性中选取
// 以上三种类型,Readonly,Partial,Pick,官方有一个称呼,把它们称为同态。
// 含义就是它们不会引入新的属性,只会用到目标类型属性(两个代数结构保持了结构不变的映射,则称这两个代数结构是同态的)。type Readonly<T> = {
readonly [P in keyof T]: T[P];
}
// readonly 是一个泛型接口,而且是一个可索引的泛型接口
// 索引签名是 P in keyof T,T 是一个索引类型的查询操作符,表示类型 T 所有属性的联合类型
// P in 相当于执行了一次遍历,会把变量 P 依次的绑定到 T 的所有属性上
// 索引签名的返回值就是一个索引访问操作符,T[P] 这里代表属性 P 所指定的类型
// 最后再加上 readonly,就可以把所有的属性变成只读,这就是 Readonly 的实现原理
type Partial<T> = {
[P in keyof T]?: T[P];
}
// Partial 的实现几乎和 Readonly 一致,只不过把只读的属性变成可选
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
}
// 第一个参数 T 指定对象,第二个参数 K 存在一个约束,K 一定要来自 T 所有属性字面量的联合类型
// 新的属性的类型一定要在 K 的属性中选取
// 以上三种类型,Readonly,Partial,Pick,官方有一个称呼,把它们称为同态。
// 含义就是它们不会引入新的属性,只会用到目标类型属性(两个代数结构保持了结构不变的映射,则称这两个代数结构是同态的)。type RecordObj = Record<'x' | 'y', Obj>
// type RecordObj = {
// x: Obj;
// y: Obj;
// }type RecordObj = Record<'x' | 'y', Obj>
// type RecordObj = {
// x: Obj;
// y: Obj;
// }条件类型
条件类型是一种由条件表达式所决定的类型。 它的形式是 T extends U ? X : Y 。如果类型 T 可以被赋值给类型 U,结果类型就是 X 类型,否则就是 Y 类型。
条件类型使类型具有了不唯一性,同样也增加了语言的灵活性。
// 条件类型:T extends U ? X : Y
// 条件类型嵌套,依次判断 T 类型,然后返回不同的字符串
type TypeName<T> =
T extends string ? 'string' :
T extends number ? 'number' :
T extends boolean ? 'boolean' :
T extends undefined ? 'undefined' :
T extends Function ? 'function' :
"object"
type T1 = TypeName<string> // type T1 = "string" 字面量类型 "string"
type T2 = TypeName<string[]> // type T2 = "object"// 条件类型:T extends U ? X : Y
// 条件类型嵌套,依次判断 T 类型,然后返回不同的字符串
type TypeName<T> =
T extends string ? 'string' :
T extends number ? 'number' :
T extends boolean ? 'boolean' :
T extends undefined ? 'undefined' :
T extends Function ? 'function' :
"object"
type T1 = TypeName<string> // type T1 = "string" 字面量类型 "string"
type T2 = TypeName<string[]> // type T2 = "object"// 分布式条件类型:(A | B) extends U ? X : Y
// (A extends U ? X : Y) | (B extends U ? X : Y)
type T3 = TypeName<string | string[]> // type T3 = "string" | "object"
// 利用这个特性可以帮助我们实现类型的过滤
type Diff<T, U> = T extends U ? never : T
type T4 = Diff<"a" | "b" | "c", "a" | "e"> // type T4 = "b" | "c"
// => (Diff<"a", "a" | "e">) | (Diff<"b", "a" | "e">) | (Diff<"c", "a" | "e">)
// => never | "b" | "c"
// => "b" | "c"
// 所以 diff 的作用就是从类型 T 中过滤掉可以赋值给类型 U 的类型// 分布式条件类型:(A | B) extends U ? X : Y
// (A extends U ? X : Y) | (B extends U ? X : Y)
type T3 = TypeName<string | string[]> // type T3 = "string" | "object"
// 利用这个特性可以帮助我们实现类型的过滤
type Diff<T, U> = T extends U ? never : T
type T4 = Diff<"a" | "b" | "c", "a" | "e"> // type T4 = "b" | "c"
// => (Diff<"a", "a" | "e">) | (Diff<"b", "a" | "e">) | (Diff<"c", "a" | "e">)
// => never | "b" | "c"
// => "b" | "c"
// 所以 diff 的作用就是从类型 T 中过滤掉可以赋值给类型 U 的类型题目
type 和 interface 区别
type 和 interface 多数情况下有相同的功能,就是定义类型。
type 不是创建新的类型,只是为一个给定的类型起一个名字。 type 还可以进行联合、交叉等操作,引用起来更简洁。
interface:创建新的类型,接口之间可以继承、声明合并。
browser
cache
ETag: W/"29322-09SpAhH3nXWd8KIVqB10hSSz66"
w/ 代表当前是弱 eTag,弱 eTag 只用于提示资源是否相同,只要求资源在语义上没有变化即可,只有资源发生根本改变,才会改变 eTag 值
语义没有变化,内容可能会有变化,例如 HTML 里的标签顺序调整,或者多出几个空格。
缓存新鲜度 = max-age || (expires - date)
当响应报文中没有 max-age、s-maxage 或 expries 字段值,但又存在强缓存控制字段时,这时会触发启发式缓存。
缓存新鲜度 = max(0,(date - last-modified)) * 10%
根据响应头报文中 date 与 last-modified 值之差与 0 取最大值取其值的百分之十作为缓存时间。
频繁变动的资源,比如 HTML,采用协商缓存。CSS、JS、图片等资源采用强缓存,使用 hash 命名。
chrome cache
正常模块加载
Mac:Command + R
Windows:Ctrl + R(F5)Mac:Command + R
Windows:Ctrl + R(F5)刷新网页,该模式下大多数资源会命中强缓存(memory cache)。
硬盘重新加载
Mac:Command + shift + R
Windows:Ctrl + shift + R(Ctrl + F5)Mac:Command + shift + R
Windows:Ctrl + shift + R(Ctrl + F5)这种模式会在资源请求头部增加 cache-control: no-cache 和 pragma: no-cache,向源服务器发起请求,确认是否存在新版本,不存在新版本使用本地缓存。
pragma 字段是为了兼容 HTTP/1.0,不推荐使用
硬盘重新加载不会清空缓存而是禁用缓存,类似开发者工具 Network 面板的 Disable cache 选项。
vue
cli
vue-cli
vue-cli 创建的项目使用 webpack 打包构建。
目前处于维护状态,不会进行特性更新,推荐使用 create-vue 。
Vue CLI is now in maintenance mode. For new projects, please use create-vue to scaffold Vite-based projects.
create-vuesupports both Vue 2 and Vue 3.
cli:https://github.com/vuejs/vue-cli
模板是动态创建的。
npm install -g @vue/clinpm install -g @vue/clivue create hello-worldvue create hello-worldcreate-vue
create-vue 创建的项目使用 vite 打包构建
npm init vue@3 // vue3 项目
npm init vue@2 // vue2 项目npm init vue@3 // vue3 项目
npm init vue@2 // vue2 项目cli:https://github.com/vuejs/create-vue
template:https://github.com/vuejs/create-vue-templates
响应式原理
compiler 过程
vue 2 parse、optimize、generate
vue 3 parse(baseParse)、transform、generate
parser 实现原理
对于 HTML 解析是有规范可循的,即 WHATWG 关于 HTML 的解析规范,其中定义了完整的错误处理和状态机的状态迁移过程。
vue.js 3 模板解析器使用递归下降算法构造模板 AST。
通过递归调用 parseChildren 函数不断地消费模板内容,返回解析得到的子节点,最终得到一棵树形结构的模板 AST。
optimize
响应式系统
- vue.js 2 响应系统和核心是 defineProperty
- 初始化时就遍历所有属性,包括用不到的属性
- vue.js 3 使用 Proxy 对象重写响应式系统
- 不需要遍历所有属性,当访问到某个属性时才会递归处理,收集依赖
- 可以监听动态新增属性
- 可以监听删除属性
- 可以监听数组的索引和 length 属性
编译优化
https://v2.template-explorer.vuejs.org
https://template-explorer.vuejs.org
优化思路:尽可能区分动态内容和静态内容,并针对不同的内容采用不同的优化策略。
vue.js 3 编译器会把编译时关键信息添加到虚拟 DOM 上,渲染器会根据这些关键信息进行优化。
vue.js 2 通过标记静态根节点,优化 diff 过程
- diff 时仍需要进行判断,存在一定的性能开销
vue.js 3 标记和提升所有的静态根节点,diff 的过程中只需要对比动态节点内容
- 动态节点收集与补丁标志(Patch Flag、Block)
- 只要存在 patchFlag 节点,就认为它是动态节点,pacthFlag 即补丁标志
- 虚拟节点的创建阶段会根据 patchFlag 提取动态子节点,并存储到 dynamicChildren 数组中,带有该属性的虚拟节点就是 块(Block)。
- Block 既可以收集自身动态子节点,还可以收集子代节点的动态子节点。
- 渲染器更新会以 Block 为维度进行更新。忽略 children 数组,直接寻找 dynamicChildren 数组进行更新。
- 除了根节点之外,任何带有结构化指令的节点都是 Block,比如 v-if、v-for。
- 静态提升
- 将静态节点提升到渲染函数之外,仅保持引用,渲染函数执行时,不会重新创建静态虚拟节点,避免额外性能开销
- 预字符串化
- 基于静态提升的优化策略
- 将大量连续静态标签节点序列化字符串,生成 static vnode
- 缓存内联事件处理函数
cache[0] || (cache[0] = ($event) => (ctx.a + ctx.b))
- 动态节点收集与补丁标志(Patch Flag、Block)
优化打包体积
- vue.js 3 中移除了一些不常用的 API
- inline-template、filter 等
- Tree-shaking
- 基于 ES Module 规范,支持静态分析,进行 Tree-shaking
vuex、pinia
https://github.com/yw0525/notes/tree/master/vue/vuex/src/store/vuex
https://github.com/yw0525/notes/tree/master/hand_writing/vuex_with_pinia
vue-router
https://router.vuejs.org/guide/advanced/navigation-guards.html#the-full-navigation-resolution-flow
https://github.com/yw0525/notes/blob/master/vue/vue_router_plus/test/src/vue-router/index.js
https://github.com/yw0525/notes/blob/master/vue/vue_router/src/router/vue-router.js
webpack
编译过程
webpack 的执行过程可以看作是一种事件驱动的事件工作流机制,这个机制可以将不同的插件串联起来,完成所有工作。
- 配置初始化
- 内容编译
- 输出编译后内容
webpack 最核心的两个部分就是负责编译的 compiler 和负责创建 bundles 的 compilation。
pnpm i webpack@^4.44.2 webpack-cli@^3.3.12 html-webpack-plugin@^4.5.0 -D pnpm i webpack@^4.44.2 webpack-cli@^3.3.12 html-webpack-plugin@^4.5.0 -Dconst path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
mode: 'development',
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist')
},
plugins: [
new HtmlWebpackPlugin()
]
}const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
mode: 'development',
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist')
},
plugins: [
new HtmlWebpackPlugin()
]
}const webpack = require('webpack')
const options = require('./webpack.config')
const compiler = webpack(options)
compiler.run(function(err, stats) {
console.log(err)
// console.log(stats.toJson())
})const webpack = require('webpack')
const options = require('./webpack.config')
const compiler = webpack(options)
compiler.run(function(err, stats) {
console.log(err)
// console.log(stats.toJson())
})webpack 初始化的时候,就已经定义好一系列钩子供我们使用。
编译流程分析:
- 开始
- 配置合并
- 实例化 compiler
- 初始化 node 读写能力
- 挂载 plugins
- 处理 webpack 内部插件(入口文件处理)
make 前流程分析:
- 实例化 compiler 对象(贯穿整个 webpack 工作过程)、由 compiler 调用 run 方法
- compiler 实例化操作
- compiler 继承 tapable,因此它具备钩子的操作能力(监听事件、触发事件、webpack 是一个事件流)
- 实例化 compiler 对象之后向它的身上挂载很多属性,其中 NodeEnvironmentPlugin 这个操作让它具备了文件读写能力
- 具备文件读写能力之后,然后将 plugins 中的插件挂载到 compiler 对象上
- 将内部默认的插件与 compiler 建立关系,其中 EntryOptionPlugin 用来处理模块 ID
- 在实例化 compiler 的时候,只是监听 make 钩子(SingleEntryPlugin)
- SingleEntryPlugin 模块的 apply 中存在二个钩子的监听
- 其中 compilation 钩子就是 compilation 具备了利用 normalModuleFactory 工厂创建一个普通模块的能力,因为它就是利用一个自己创建的模块来加载需要被打包的模块
- 其中 make 钩子在 compiler.run 时会被触发,意味着某个模块打包之前的准备工作就完成了
- addEntry 方法调用
- run 方法执行
- run 方法里就是一堆钩子按照顺序触发(beforeRun、run、compile)
- compile 方法执行
- 准备参数(其中 normalModuleFactory 是后续用于创建模块)
- 触发 beforeCompile
- 将第一个参数传给一个函数,创建一个 compilation(newCompilation)
- 在调用 newCompilation 的内部
- 调用了 createCompilation
- 触发 this.compilation 钩子和 compilation 的监听
- 当创建 compilation 对象之后,触发 make 钩子
- 当触发 make 钩子监听时,将 comilation 对象传递作为参数传递
addEntry 流程分析:
- make 钩子在被触发时,接收 compilation 实例,它由很多属性。
- 从 compilation 解构三个值
- entry:当前需要被打包的模块的相对路径(./src/index.js)
- name:main
- context:当前项目的根路径
- dep 是对当前入口模块的依赖关系进行处理
- 调用 addEntry 方法。
- 在 compilation 实例身上存在一个 addEntry 方法,然后内部调用 _addModuleChain 方法去处理依赖
- 在 compilation 中可以通过 NormalModuleFactory 工厂来创建一个普通的模块对象
- 在 webpack 内部默认开启了一个 100 并发量的打包操作,我们看到的是 normalModule.create()
- 在 beforeResolve 内部会触发一个 factory 钩子监听(这部分操作用来处理 loader,不会重点分析)
- 上述操作完成之后,获取到一个函数存在 factory 中,然后对它进行立即调用,在这个函数调用里又触发了一个 resolver 的钩子(处理 loader,拿到 resolver 方法之后意味着所有的 loader 处理完毕)
- 调用 resolver() 方法之后,就会进入到 afterResolve 这个钩子里,然后就会触发 new NormalModule
- 完成上述操作之后就将 module 进行保存和一些其他属性参加
- 调用 buildModule 方法开始编译,内部调用 build 方法,内部返回并调用 doBuild
vite
架构原理
Vite 底层使用两个构建引擎,Esbuild 和 Rollup。
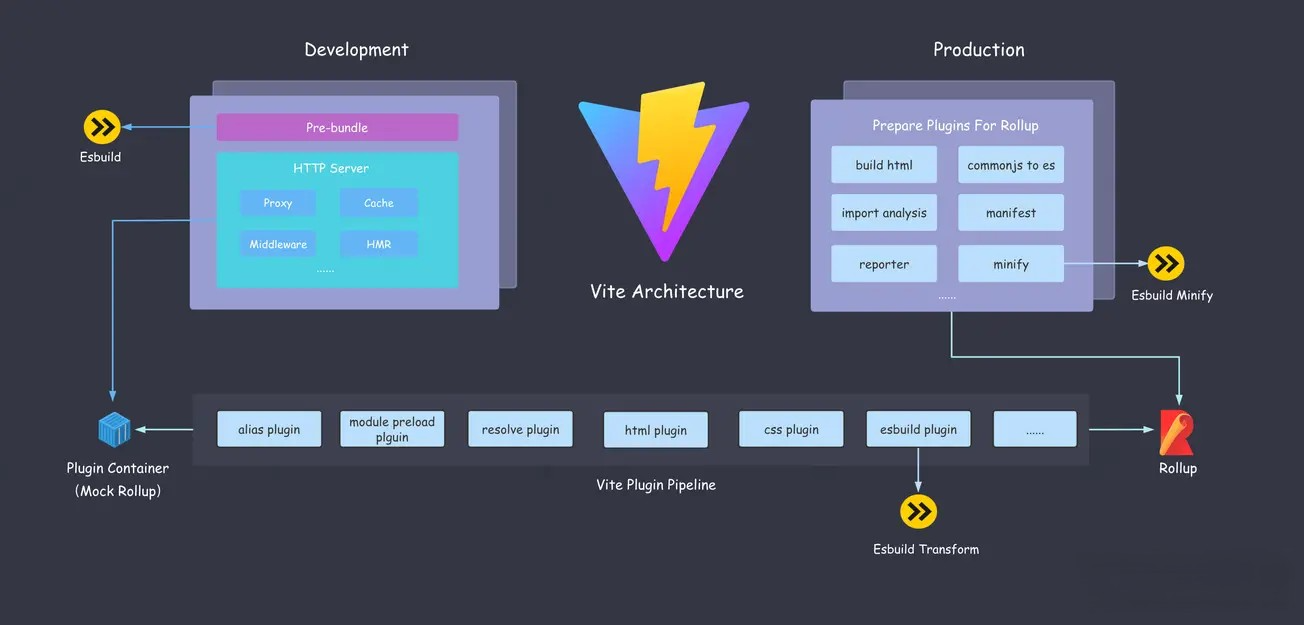
EsBuild
依赖预构建阶段,作为 bundler(打包工具) 使用
语法转译,将 Esbuild 作为 transformer 使用
- TS 或者 JSX 文件转译,生产环境和开发环境都会执行
- 替换原来的 Babel 和 TSC 功能
代码压缩,作为压缩工具使用
- 在生产环境通过插件的形式融入到 Rollup 的打包流程
- JS 和 CSS 代码压缩
Vite 利用 EsBuild 各个垂直方向的能力(Bundler、Transformer、Minifier),给 Vite 的高性能提供了有利的保证。
Vite 3.0 支持通过配置将 EsBuild 预构建同时用于开发环境和生产环境,默认不会开启,属于实验性质的特性。
Rollup
- 生产环境下,Vite 利用 Rollup 打包,并基于 Rollup 本身的打包能力进行扩展和优化。
- CSS 代码分割
- 将异步模块 CSS 代码抽离成单独文件,提高线上产物的缓存复用率
- 自动预加载
- 为 入口 chunk 的依赖自动生成
<link rel="modulepreload" >,提前下载资源,优化页面性能 - 关于 modulepreload
- 为 入口 chunk 的依赖自动生成
- 异步 chunk 加载优化
- 自动预加载公共依赖,优化 Rollup 产物依赖加载方式
- CSS 代码分割
- 兼容插件机制
- 无论是开发阶段还是生产环境,Vite 都根植于 Rollup 的插件机制和生态
在 Vite 中,无论是插件机制还是打包手段,都基于 Rollup 来实现,可以说 Vite 是对于 Rollup 的一种场景化的深度拓展。
插件流水线
在开发阶段 Vite 实现了一个按需加载的服务器,每一个文件都会经历一系列的编译流程,然后再将编译结果响应给浏览器。 在生产环境中,Vite 同样会执行一系列编译过程,将编译结果交给 Rollup 进行模块打包。
这一系列的编译过程指的就是 Vite 的插件工作流水线(Pipeline),插件功能是 Vite 构建的核心。
在生产环境中 Vite 直接调用 Rollup 进行打包,由 Rollup 调度各种插件。 在开发环境中,Vite 模拟了 Rollup 的插件机制,设计了一个 PluginContainer 对象来调度各个插件。
PluginContainer 的实现主要分为两部分:
- 实现 Rollup 插件钩子的调度
- 实现插件钩子内部的 Context 上下文对象
Vite 插件的具体执行顺序如下:
- 别名插件:
vite:pre-alias和@rollup/plugin-alias,用于路径别名替换。 - 用户自定义 pre 插件,即带有
enforce: "pre"属性的自定义插件。 - vite 核心构建插件。
- 用户自定义普通插件,即不带有
enforce属性的自定义插件。 - vite 生产环境插件和用户插件中带有
enforce: "post"属性的插件。 - 开发阶段特有的插件,包括环境变量注入插件
clientInjectionsPlugin和 import 语句分析及重写插件importAnalysisPlugin。
Vite 内置的插件包括四大类:
- 别名插件
- 核心构建插件
- 生产环境特有插件
- 开发环境特有插件